Section spec defined the behavior of a specializer ![]()
A specializer produces special cases from general procedures. This
chapter exhibits one such system (![]() ), and uses it to understand
the practice of polyvariant specialization. First I introduce my
notation and give a simple online specializer for a typed
), and uses it to understand
the practice of polyvariant specialization. First I introduce my
notation and give a simple online specializer for a typed
![]() -language. I then extend the calculus with products,
booleans, and sums. The remaining sections discuss lifting,
memoization, recursion, and compiler generation. The correctness of
-language. I then extend the calculus with products,
booleans, and sums. The remaining sections discuss lifting,
memoization, recursion, and compiler generation. The correctness of
![]() is considered in Section crct.
is considered in Section crct.
This chapter is generally a review of Partial Evaluation (PE) practice; [CoDa98] and [JoGoSe93] are the standard texts of the field and may be considered references of first resort. [Jones91] is a theoretical introduction to operational behavior of specializers, and [Jones88] provides a practical description of first-order PE. [WCRS91, Consel88, Thiemann96, BoDa91, BiWe93] are system descriptions.
Figure domains gives the grammar of the object language and
its type structure. It also defines some domains [Reynolds97] and
their associated metavariables. The language is a call-by-value
![]() -calculus extended with integer constants, primitives,
conditionals, a lift annotation, and explicit types on abstractions.
I use the
-calculus extended with integer constants, primitives,
conditionals, a lift annotation, and explicit types on abstractions.
I use the ![]() face for the terms of the object
language. I use
face for the terms of the object
language. I use ![]() to denote a generic, ``black box'' binary
primitive operation.
to denote a generic, ``black box'' binary
primitive operation. ![]() mark manipulation of the terms
of the
mark manipulation of the terms
of the ![]() -language's syntax and types. Frames appear in
patterns and expressions. The slots of the term in the frame are
either metavariables or parenthesized expressions in the metalanguage.
-language's syntax and types. Frames appear in
patterns and expressions. The slots of the term in the frame are
either metavariables or parenthesized expressions in the metalanguage.
Figure specfn gives a specializer ![]() . Roman typeface is
used for metalanguage constructs such as ``
. Roman typeface is
used for metalanguage constructs such as ``![]() '' and ``
'' and ``![]() ''.
``
''.
``![]() '' denotes pattern
matching where the metavariables only match members of the appropriate
domain. I use
'' denotes pattern
matching where the metavariables only match members of the appropriate
domain. I use ![]() to denote the
extension of the environment
to denote the
extension of the environment ![]() with a binding from the variable
with a binding from the variable
![]() to the value
to the value ![]() , and [] to denote the empty environment.
, and [] to denote the empty environment.
Note that several operators have two notations, one in the
metalanguage and one in the object language. For example lambda
is the syntax for a procedure and ![]() is a mathematical function;
is a mathematical function;
* denotes the product type and ![]() denotes the product of two
domains.
denotes the product of two
domains.
![]() is a partial-evaluation function, it assigns a meaning
from
is a partial-evaluation function, it assigns a meaning
from ![]() to a source text with environment. The difference from the
ordinary semantics is that
to a source text with environment. The difference from the
ordinary semantics is that ![]() contains
contains ![]() , whose members represent
computations dependent on unknown values, that is, residual code. I
say the specializer emits residual code.
, whose members represent
computations dependent on unknown values, that is, residual code. I
say the specializer emits residual code.
The lift primitive forces its argument to become residual code; I
call it an annotation because it has no meaning in the ordinary,
one-stage semantics.
Figure helpers defines the reflection and reification
functions ![]() and
and ![]() (up from the subject language and down from
the metalanguage). They operate as coercions between code and data;
understanding them is not essential to this chapter.
(up from the subject language and down from
the metalanguage). They operate as coercions between code and data;
understanding them is not essential to this chapter. ![]() is invoked
in the term for the meaning of
is invoked
in the term for the meaning of lift.
An important property that this specializer lacks is safety. ![]() may lose effects or duplicate computations. For example, the rule for
static function application works by substitution, so if the
computation of an argument has a side-effect, but is then passed to a
function that never refers to the value, the effect is lost.
Similarly, if the value is used more than once, the effect may be
duplicated.
may lose effects or duplicate computations. For example, the rule for
static function application works by substitution, so if the
computation of an argument has a side-effect, but is then passed to a
function that never refers to the value, the effect is lost.
Similarly, if the value is used more than once, the effect may be
duplicated.
Most systems use let-insertion [BoDa91] to guarantee safety. The implementation of let-insertion is closely related to that of booleans, explained below [Bondorf92, Danvy96].

![{ml {Spec} : {Exp} {evalsto} {Env} {evalsto} {M}
{Spec} {frame-box {e0}{diamond}{e1}} {rho} = match {tab-stop}({Spec} {e0} {rho}, {Spec} {e1} {rho})
{tab}({s0}, {s1}) {evalsto} {s0} {diamond} {s1}
{tab}({d0}, {d1}) {evalsto} {frame-box {d0} {diamond} {d1}}
{Spec} {frame-box {v}} {rho} = {rho} {v}
{Spec} {frame-box {m k}} {rho} = {m k}
{Spec} {frame-box {c lambda {v}:{m t}.{e}}} {rho} = ({lambda}{vp}.{Spec} {e} ([{v}{mapsto}{vp}]{rho})){subt}
{Spec} {frame-box {e0} {e1}} {rho} = match {tab-stop}({Spec} {e0} {rho}, {Spec} {e1} {rho})
{tab}({m f}, {m m}) {evalsto} {m f} {m m}
{tab}({d0}, {d1}) {evalsto} {frame-box {d0} {d1}}
{Spec} {frame-box {c lift {e}}} {rho} = {R} ({Spec} {e} {rho})
{Spec} {frame-box {c if0 {e0} {e1} {e2}}} {rho} = match {tab-stop}({Spec} {e0} {rho})
{tab}{s0} {evalsto} if 0 = {s0} then ({Spec} {e1} {rho}) else ({Spec} {e2} {rho})
{tab}{d0} {evalsto} {tab-stop}let {tab-stop}{d1} = {Spec} {e1} {rho}
{tab}{tab}{tab}{d2} = {Spec} {e2} {rho}
{tab}{tab}in {frame-box {c if0 {d0} {d1} {d2}}}
}](32.gif)

Note that the if0 clause requires that when a conditional has
dynamic predicate, then both arms are also dynamic. Section features below shows how to implement a conditional without this
restriction.
![]() is similar to the
is similar to the ![]() -mix of [GoJo91], but
-mix of [GoJo91], but
![]() -mix uses uses a two-level input language where source
-mix uses uses a two-level input language where source
![]() s have been labeled either for execution or immediate
residualization.
s have been labeled either for execution or immediate
residualization. ![]() reserves judgment until the function is
applied;
reserves judgment until the function is
applied; ![]() depends on a lift annotations to emit a
depends on a lift annotations to emit a lambda.
Note that many cases are missing from ![]() . I assume that all input
programs are type-correct and lift annotations appear as necessary, so
these situations never occur. Placement of the lifts is crucial to
successful staging: too many lifts and
. I assume that all input
programs are type-correct and lift annotations appear as necessary, so
these situations never occur. Placement of the lifts is crucial to
successful staging: too many lifts and ![]() degenerates into the
curry function; too few and
degenerates into the
curry function; too few and ![]() fails to terminate. Typically binding time analysis (BTA) is combined with programmer annotations
to insert the lifts. For example, if
fails to terminate. Typically binding time analysis (BTA) is combined with programmer annotations
to insert the lifts. For example, if ![]() then
then ![]() requires
requires ((lift
a) rather than ![]() b)
b)(a. This kind of lift is
obvious, and is easily handled by BTA. As an example of the kind of
lift that cannot be easily automated, consider the tail-recursive
function in Figure tailloop, where ![]() b)
b)e is dynamic and b
is static. Unless we manually lift r to dynamic, ![]() will
diverge.
will
diverge.
fun tail_loop b e r = if e = 0 then r else tail_loop b (e-1) (b*r)val power b e = tail_loop b e 1
If each variable and procedure always has the same binding time, then
a partial evaluator is said to be monovariant in binding times.
The prototypical monovariant system is ![]() -mix. Monovariant BTA
is well-understood and can be efficiently implemented with
type-inference [Henglein91]. The problem with this kind of
system is that frequently a procedure is applied to values with
different binding times. For example, in one context I might apply
-mix. Monovariant BTA
is well-understood and can be efficiently implemented with
type-inference [Henglein91]. The problem with this kind of
system is that frequently a procedure is applied to values with
different binding times. For example, in one context I might apply power to static base and exponent, but in another, to dynamic base
and static exponent.
If the binding times are context sensitive, then a partial evaluator
is said to be polyvariant in binding times. A polyvariant BTA is one
that effectively places lifts for this kind of system. Polyvariant
BTA usually implemented with abstract interpretation [Consel93].
Thus a given piece of syntax may be both executed by ![]() and
emitted as residual.
and
emitted as residual.
This section adds product and sum types to the specializer. Inductively defined types are similarly easy, but other types such as polymorphism and modules are the subject of active research.
The specializer above treats primitives uniformly. A primitive application is either performed at specialization time or emitted as residual code. In particular, if a primitive has one static and one dynamic argument, then the static one must be lifted, throwing information out of the compiler. But many primitives have algebraic properties that allow us to preserve some information.
Figures products2, bools, and sums2 extend the
formal system to products, booleans, and sums, respectively. Sums are
a generalization of booleans as ![]() =
= ![]() +
+ ![]() .
.

The product types allow the following:
![]()
where ![]() . In partial
evaluation jargon, the value of
. In partial
evaluation jargon, the value of (0,d) is called a partially
static structure.
This if and if0 from Figure specfn are fundamentally
different:
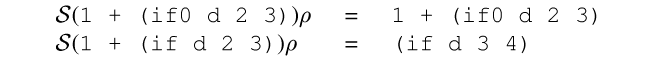
Normally, we think of specialization as either performing or emitting
each operation of a program. But this specialization of if
requires that the addition be performed twice. How can ![]() return
into the addition twice twice?
return
into the addition twice twice?
There are two standard solutions: continuation-based specialization
[Bondorf92], and the shift and reset control operators used here.
Shift is similar to Scheme's call/cc (call with current
continuation), but the extent of ![]() is limited by reset. See
Section shiftreset for a explanation of these control
operators.
is limited by reset. See
Section shiftreset for a explanation of these control
operators.
Section mycogen shows how to get the same result by using a source language in continuation-passing style.
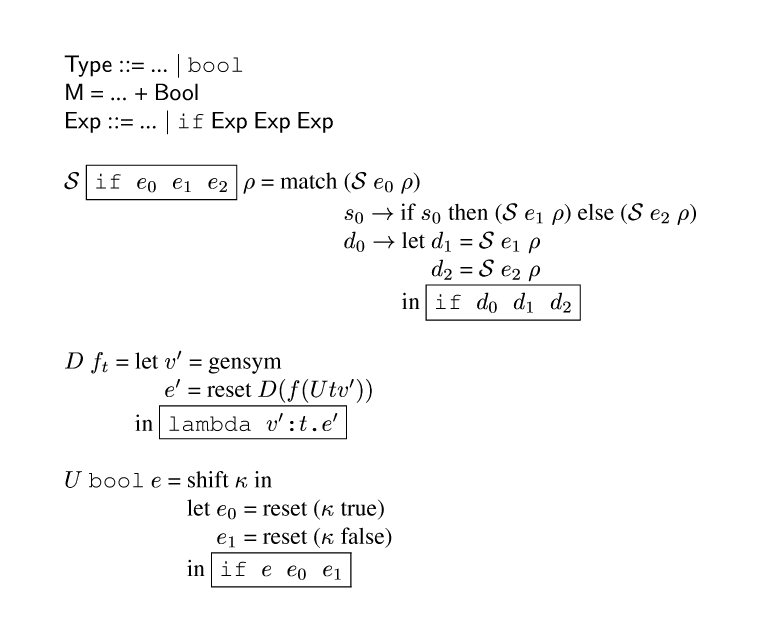
![{ml {Type} {syn} ... {or} {Type} + {Type}
{M} = ... + (inL {M}) + (inR {M})
{Exp} {syn} {tab-stop}... {or} {c inL} {Exp} {or} {c inR} {Exp}
{tab} {or} {c case} {Exp} {Var} {Exp} {Var} {Exp}
{Spec} {frame-box {c inL {e}}} {rho} = inL ({Spec} {e} {rho})
{Spec} {frame-box {c inR {e}}} {rho} = inR ({Spec} {e} {rho})
{Spec} {frame-box {c case {e} {m v_0} {e0} {m v_1} {e1}}} {rho} = match {tab-stop}{Spec} {e} {rho}
{tab}inL {m0} {evalsto} {Spec} {e0} ([{m v_0} {mapsto} {m0}] {rho})
{tab}inR {m1} {evalsto} {Spec} {e1} ([{m v_1} {mapsto} {m1}] {rho})
{R} (inL {m0}) = {frame-box {c inL ({R} {m0})}}
{R} (inR {m0}) = {frame-box {c inR ({R} {m0})}}
{L} {frame-box {m t} + {m t'}} {e} = {tab-stop}shift {kappa} in
{tab}let {tab-stop} {m v_0} = gensym
{tab}{tab}{m v_1} = gensym
{tab}{tab}{e0} = reset ({kappa} (inL ({L} {m t} {m v_0})))
{tab}{tab}{e1} = reset ({kappa} (inR ({L} {m t'} {m v_1})))
{tab}in {frame-box {c case {e} {m v_0} {e0} {m v_1} {e1}}}}](43.gif)
We originally said that a specializer does ``all the work possible given only some of the input''. The previous section gave rules to find and perform this work. The problem is that blind application of these rules often finds too much work, and creates many specialized procedures that do not run fast enough to pay for their size and number. In particular, since the rule for function application may inline, use of recursion may result in infinite unfolding, and thus non-termination of the specializer.
The lift term is the fundamental form of control, but is
insufficient. For example, in the tail-recursive power function
in Figure tailloop we must lift r to prevent
non-termination. But if e is static, then lifting r prevents
the simple static result we surely want.
Nitrous and Schism use lift languages to give the programmer
conditional lifting. Basically they work by reifying binding times.
Other systems such as [WCRS91] contain analyses that identify and
perform this lift, but miss-identify others. I believe that full
automation (i.e. elimination of lift from the input language) is
not yet feasible; binding-time and staging systems need some kind of
manual control.
Memoization is a standard technique to avoid repeated computation. It plays an important role in some specializers, including ours. This section explains the distinction by looking at dynamic loops. We call specializers that use this kind of memoization polyvariant, and those that do not monovariant.
Using the rules in Figure specfn above, a loop must be built with a fixed-point operator (this is one of the things that the ML syntax obscures). The type of the operator depends on how much of the recursion is to be expanded. In other words, the source program must be adjusted to support different binding times. Figures dp1 and dp2 show two versions of the power function specialized with Type Directed Partial Evaluation (TDPE) [Danvy96][footnote: Danvy reports that a future version of TDPE does not have this restriction.]. A polyvariant specializer does not have this limitation, as the example in Figure sp1 demonstrates.
(define (power-abs n)
(lambda (*)
(lambda (a)
(fix1 (lambda (loop)
(lambda (n)
(if (zero? n)
1
(* a (loop (- n 1))))))))))
(define-base-type Int "i")
(define-compound-type Times ((Int Int) => Int) "*" alias)
(define (fix1 F) (lambda (x) ((F (fix1 F)) x)))
(residualize (power-abs 5) '(Times -> Int -> Int))
-->
(lambda (*)
(lambda (i0)
(* i0 (* i0 (* i0 (* i0 (* i0 1)))))))
(define (dpower-abs fix2 * zero? -) (fix2 (lambda (loop) (lambda (x n) (if (zero? n) 1 (* x (loop x (- n 1))))))))(define-base-type Bool "b") (define-compound-type Minus ((Int Int) => Int) "-" alias) (define-compound-type Zero? (Int -> Bool) "zero?" alias)
(define-compound-type Fix2 ((((Int Int) => Int) -> ((Int Int) => Int)) -> ((Int Int) => Int)) "fix2" alias)
(define (fix2 F) (lambda (x y) ((F (fix2 F)) x y)))
(residualize dpower-abs '((Fix2 Times Zero? Minus) => (Int Int) => Int))
-->
(lambda (fix2 * zero? -) (lambda (i3 i4) ((fix2 (lambda (x0) (lambda (i1 i2) (if (zero? i2) 1 (* i1 (x0 i1 (- i2 1))))))) i3 i4)))
At a call site, a monovariant specializer like ![]() -mix [GoJo91] either inlines or residualizes. A polyvariant specializer has
the option of emitting a call to a specialized procedure defined
elsewhere, and passing just the dynamic arguments. This specialized
procedure may be called from several different places.
-mix [GoJo91] either inlines or residualizes. A polyvariant specializer has
the option of emitting a call to a specialized procedure defined
elsewhere, and passing just the dynamic arguments. This specialized
procedure may be called from several different places.
A polyvariant specializer uses its memo-table to discover dynamic fixed points. Before creating a specialized version of a procedure, a polyvariant system checks to see if it already has a version of that procedure specialized to those static values, and if so, creates a call to the already defined procedure.
This use of memoization is more than just a convenience or a simple performance improvement. Polyvariance is fundamentally more powerful because zero, one, or more fixed points may be created from a single source fixed point. Furthermore, the types of the residual fixed-points may be different from the types of the input fixed points. The standard example is Ackermann's function specialized to its first argument, resulting in two different fixed points, as in Figure sack. Figure mize shows an example of a loop that unrolls several times before the static values match and the dynamic loop is found. A more practical example is the generation of KMP string-matching by specialization [CoDa89]. None of these results can be duplicated with a monovariant system. It can be dangerous, however, to rely on the memo-table to find fixed-points.
(similix 'power (list '*** 5) "source.sim") --> (define (power5 b) (* b (* b (* b (* b (* b 1))))))
(similix 'power (list '*** '***) "source.sim") --> (define (power-dd b e) (if (= e 0) 1 (* b (power-dd b (- e 1)))))
*** indicates a dynamic
value, the contents of source.sim appear in Figure spc.
(define (power b e)
(if (= e 0)
1
(* b (power b (- e 1)))))
(define (ack m n)
(cond ((zero? m) (+ n 1))
((zero? n) (ack (- m 1) 1))
(else (ack (- m 1) (ack m (- n 1))))))
(define (mize n m d e)
(if (e) n
(let* ((n1 (- n d))
(n2 (if (< n1 0) (+ n1 m) n1)))
(mize n2 m d e))))
source.sim
(similix 'ack (list 2 '***) "source.sim")
-->
(define (ack2 n)
(if (zero? n)
(ack1 1)
(ack1 (ack2 (- n 1)))))
(define (ack1 n)
(if (zero? n)
2
(+ (ack1 (- n 1)) 1)))
(similix 'mize (list 0 5 2 '***) "source.sim")
-->
(define (mize052 e)
(cond ((e) 0) ((e) 3)
((e) 1) ((e) 4)
((e) 2)
(else (mize052 e))))
The question remains: when should the system inline, and when should it specialize, that is, test the memo-table and form a call? While it is safe to always specialize, the resulting code has many trivial calls. Many systems, including ours, use the dynamic-conditional heuristic [BoDa91]. The heuristic suggests that calls be inlined unless the body of the procedure contains a control-flow branch depending on dynamic values. Such a branch is known as a dynamic conditional. The intuition behind the heuristic is that if there is no dynamic conditional then inlining is safe because any resulting non-termination would also be present in ordinary execution of the source program[footnote: This heuristic is very simple and aggressive. This kind of manual control of inlining sometimes produces unexpectedly large results. Compilers for functional languages such as SML [ApMa91] and Haskell [JHHPW93] make much more sophisticated inlining decisions. One could use the safe, always-specialize heuristic, and use sophisticated inlining as a post-pass to remove the trivial calls. In the run-time environment we are interested in, feedback from execution or a inexpensive approximation may substitute for sophisticated inlining decisions.].
The price is that polyvariant specialization is more difficult to implement, type, and reason about. Bit-addressing makes essential use of memoization.
If we used a literal implementation of ![]() to specialize programs,
then every time we generate a residual program, we would also traverse
and dispatch on the source text. The standard way to avoid this
repeated work is to introduce another stage of computation. That is,
to use a compiler generator cogen instead of a specializer spec. The compiler generator converts
to specialize programs,
then every time we generate a residual program, we would also traverse
and dispatch on the source text. The standard way to avoid this
repeated work is to introduce another stage of computation. That is,
to use a compiler generator cogen instead of a specializer spec. The compiler generator converts ![]() into a synthesizer of
specialized versions of
into a synthesizer of
specialized versions of ![]() :
:
These systems are called compiler generators because if
The standard way of implementing a compiler generator begins with a
static analysis of the program text, then produces the synthesizer by
syntax-directed traversal of the text annotated with the results of
the analysis. Cogen knows what will be constant but not the constants
themselves. We refer to this information binding times, it
corresponds to the injection tags on members of ![]() . We say
members of
. We say
members of ![]() are static and members of
are static and members of ![]() are dynamic. The binding times form a lattice because they represent
partial information. It is always safe for the compiler to throw away
information; this is called lifting and is the source of the
are dynamic. The binding times form a lattice because they represent
partial information. It is always safe for the compiler to throw away
information; this is called lifting and is the source of the lift annotation in the ![]() -language. Thus the bottom of the
lattice is dynamic.
-language. Thus the bottom of the
lattice is dynamic.
[BoDu93] shows how to derive a cogen from ![]() -mix in two
steps. The first step converts a specializer into a compiler
generator by adding an extra level of quoting to
-mix in two
steps. The first step converts a specializer into a compiler
generator by adding an extra level of quoting to ![]() so static
statements are copied into the compiler and dynamic ones are emitted.
The second step involves adding a continuation argument to
so static
statements are copied into the compiler and dynamic ones are emitted.
The second step involves adding a continuation argument to ![]() to
allow propagation of a static context into the arms of a conditional
with a dynamic test. One of the interesting results of [Danvy96]
is how this property (the handling of sum-types and let-insertion) can
be achieved while remaining in direct style by using shift/reset.
to
allow propagation of a static context into the arms of a conditional
with a dynamic test. One of the interesting results of [Danvy96]
is how this property (the handling of sum-types and let-insertion) can
be achieved while remaining in direct style by using shift/reset.
A remarkably pleasing though seemingly less practical way of
implementing ![]()
![]()
Specializers are classified as either offline or online. An online system works in one pass. Roughly, offline systems are suitable for compiler generation via self-application, and online systems are not. An offline system works in two phases. First it performs a whole-program analysis phase (the BTA) independent of the static values, and then it performs a specialization phase. Ideally, in an offline system all perform-vs-emit decisions are made in the BTA, but in reality most offline systems include polyvariance, which involves value-dependent decisions. Further hybridization is explored in [Sperber96]. The system from chapter system memoizes on binding times and static values, so it is also a hybrid. As a result, procedure contents are treated offline, but procedure calls are treated online. The system in Section simple is online. Similix (see Section ba) is offline.
This chapter covers the theory and practice of specialization. In order to understand the next chapter, it is important to understand that the specializer performs constant propagation, function inlining, and memoization.