Alternatives
This section compares my approach to some existing alternative
techniques. This could be considered either `pre-design' work, or
`related work'. Precompilation and buffering are two other ways of
working around the performance problems of interpreters. Instead of
implementing cogen directly, it's possible to generate it using a
self-applicable partial evaluator. Finally, lisp systems with macros
are considered.
- precompilation vs RTCG
- buffering and APL
- self application and cogen
- lisp and macros
Precompilation vs RTCG
In the power example, instead of generating power-20 at run time
you could compile many different power procedures and dispatch at run
time. This is precompilation: a space-time trade-off where a
look-up table with programs for table entries replaces a more general
program.
But which values do you precompile for? For power, you could
probably use the first 100 integers pretty well, but in general,
success depends on predicting the distribution of the dynamic values.
As the language becomes more complex, its parameter space grows, and
its use becomes more dynamic, the code space required to precompile it
explodes exponentially. Pike's bitblt handled 1944 (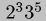 )
different cases [blit]. The same effect is visible in most any
math vector library [CVL][NAG], or in my Shape language
[Shape].
)
different cases [blit]. The same effect is visible in most any
math vector library [CVL][NAG], or in my Shape language
[Shape].
The precompiled procedures can be hand-written for speed or
automatically generated. Hand-writing requires duplicate code, but
allows for tweeking. Automation requires the same compiler as RTCG
requires.
Though all too often the meta-language used is cpp or awk
[links!], in any language with a decent macro-system (metalanguage),
and lisp in particular, precompilation is in fact a fundamentally
important technique [On-Lisp].