 ps
ps
 ps
psThis chapter reports on the building and measurement of several media processing kernels. First I ignore automatic specialization and compare the manual implementation of the alternative strategies (interpreted, buffered, and specialized) from Section tradeoffs. Then I present the benchmark data of the residual code from Nitrous and Simple, the two implementations of bit-addressing. A partial implementation (cyclic values only) is described briefly in Appendix ba.
Except as noted below, the methodology is as follows: I use GCC
v2.7.2 with the -O1 option. Although I collected some data with
the -O2 option, it was not significantly different, so I discarded
it.
Each of the examples was run for 1000 iterations, while real elapsed
time was measured with the gettimeofday system call. The whole
suite was run five times, and the best times were taken.
The legend of each bar-chart indicates which data-sets come from which machines. Four machines were used to collect the data:
The height of a bar indicates the ratio of the two execution times specified in the caption.
The software is available from http://www.cs.cmu.edu/~spot. The distributions contain the source
code for all the programs measured below.
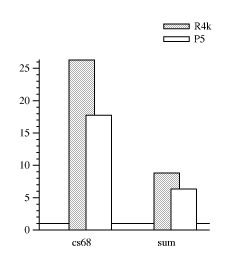
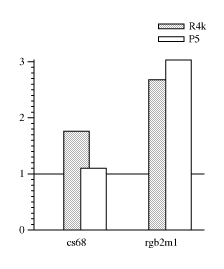
The graphs in Figure genspec compare specialization to
interpretation and buffering. The general, unspecialized versions
here are built on load_sample directly (like sum in Figure
sum-signal) rather than with the interface in Figure sig. As expected, the unspecialized programs run many times slower
than their specialized counterparts.
The buffered code uses typical operations on vectors of whole-word
integers such as multiply every member by a scalar, or add one vector
into another. It also uses encode and decode routines that copy a
signal from its packed representation into a whole-word vector. These
routines have a special case for bytes, otherwise they call load/store_sample. The vectors are 200 words long. Cs68 uses three
passes, and rgb2m1 uses ten. The code appears in Appendix manual.
[ThoDa95] analizes buffered audio synthesis when all the data fit into an on-chip cache. They find (and this is corroborated by anecdotal evidence) that buffering reduces bandwidth by about 30%, and the cost is fairly independent of the number of passes over the buffers. This data set indicates that the cost can be more than 200% and may grow with the number of passes. The lower overheads may result from using application-specific vector primitives. In other words, some amount of manual specialization has already taken place.
ps
ps
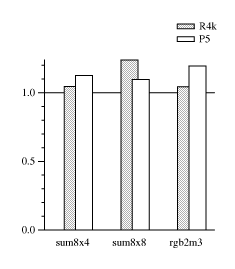
Next, I compare using char* pointers and reading individual bytes
to reading whole words and using shift and masks (as bit-addressing
does). Figure bitsw shows that reading words runs
slightly faster despite using more instructions. I expect that these
results are rather dependent on the microarchitecture. The sum8x4 and
sum8x8 benchmarks add up the members of a contiguous vector of bytes.
The byte-loop is unrolled four and eight times, respectively (the word
version is always unrolled four times). The rgb2m3 benchmark is
explained below.
 ps
ps
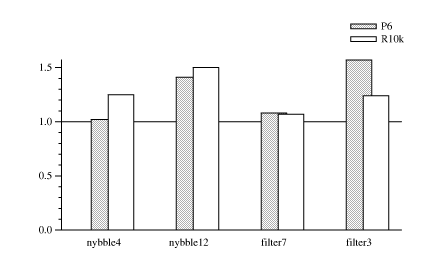
This section presents the a small data-set from the Nitrous system.
It compares bit-addressing and automatic specialization to
hand-written code. The programs of Figure nitrous-times were
implemented in root, including the cache and signal library. All
the residual root code is translated to one large C procedure by
using GCC's indirect-goto extension for jumps. These examples were
run on 2500 bytes of data instead of 4000.
 ps
psroot code automatically specialized by Nitrous
normalized to time of hand-specialized code.
In order to scale-up the examples I built Simple, an online
specializer that does not use shift/reset or continuations and
restricts dynamic control flow to loops (i.e. sum and arrow types are
not fully handled). All procedure calls in the source programs are
expanded, but the input language is extended with a while-loop
construct that may be residualized:
![]()
which is equivalent to the definition and application of the recursive
procedure:
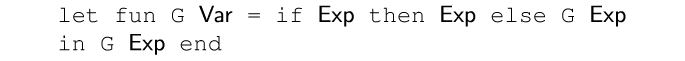
The loop construct is specialized according to the dynamic conditional heuristic and memoization: it is inlined until the predicate is dynamic, then the loop is entered and unrolled until the predicate is dynamic again. At this point, the static part must match the static part at the previous dynamic conditional.
As described in Chapter pe, because Simple does not perform let-insertion, it may duplicate or forget side-effects. Since GCC performs common subexpression elimination, most but not all of the duplication is eliminated.
The input to Simple is also the Sal language, but with an ML-like
syntax and the above restrictions. Examples of its use appear in
Figures assumptions and fircode, and Appendix benche. The information is specified with unique names (constants
really) created with a quote syntax. The names are ordinary
first-class values. The clone primitive copies a data-structure
including sharing information and creates a new value with the same
pattern of sharing internally, but that doesn't share with anything
else.
Simple differs from Nitrous in several places. In Nitrous, a generated compiler knows the shapes of the dynamic values, which are the names of their location in the residual code. Early equality works by comparing these locations. In Simple, a dynamic value is associated with an expression. Early equality works by textual equality of these expressions.
Simple does not provide premultiplied cyclic values (see Section cyc-rep). Nor does it use late normalization (see Section npi).
Simple is implemented in SML/NJ without concern for execution speed. The specializer requires fractions of a second to produce the examples presented here.
The main example built with Simple is an audio/vector library. It
provides the signal type, constructors that create signals from
scalars or sections of memory, combinators such as creating a signal
that is the sum of two other signals, and destructors such as copy
and reduce. The vector operations are suspended in constructed
data until a destructor is called. Figure fir contains a
graphical representation of this kind of program.
Figure sig gives the signature for part of the library. The semantics and implementation are mostly trivial, most of the code appears in Appendix signals. One exception is that operations on multiple signals use a conjunction of the end-tests, as described in Section multiple. Consider the end-test of an infinite signal such as a constant or noise (a signal of pseudo-random numbers). It should return true because these signals can end anywhere, rather than returning false because they never end.
sig type samp type signal type baddress type binop = samp * samp -> sampfun vector_signal: baddress * baddress * int * int -> signal fun constant: samp -> signal
fun map: (samp -> samp) * signal -> signal fun map2: binop * signal * signal -> signal fun delay1: signal * samp -> signal fun scan: signal * samp * binop -> signal fun lut: baddress * signal -> signal fun sum_tile: samp * signal * int -> signal
fun copy: signal * signal -> unit fun reduce: signal * binop * samp -> samp
fun filter: signal * (samp list) * (samp list) -> signal fun fm_osc: signal * int * baddress * int * signal * int -> signal end
This delay operator returns a signal of the same length as its input,
thus it loses the last sample of the input signal. The other
possibility (that it returns a signal one longer) requires sum-types
because there would be a dynamic conditional in the next
method.
The filter combinator is built out of a recursive series of delays,
maps, and binops. Similarly, the wavetable combinator is built from
simpler components. Lut transforms a signal by looking up the
samples in an array in memory where the translations are stored one
per word. A general version that used another signal as the
look-up-table would require a translate method, not shown here.
Translate is also required for the 2D graphics interface, but I
have not yet finished with it so I cannot present it here.
A feedback combinator can be made in a higher-order language. Show the code.
With this system, interleaved vectors are stored in the same range of memory, Figure combined(c) is an example of three interleaved vectors. With an ordinary vector package, if one passes interleaved vectors to a binary operation, then each input word is read twice. An on-chip hardware cache makes this second read inexpensive, but with the software cache the situation is detected once at code-generation time. Specialization with sharing can replace a cache hit with a register reference.
Collapsible protocol languages such as [HaRe96, ProWa96] can handle more advanced control flow (our signals are push or pull, not both), but these systems do not address bits. The same is true of synchronous real-time languages like Signal [GuBoGaMa91] and Lustre [CPHP87]. Their compilers are mostly concerned with deriving global timing from local behavior.
Past work in bit-level processing has not emphasized implementation on word machines. Although C allows one to specify the number of bits used to store a field in a structure, it does not provide for arrays of bits. The hardware design language VHDL [IEEE91]) allows specification of signals of particular numbers of bits, but lacks a compiler that produces fast code.
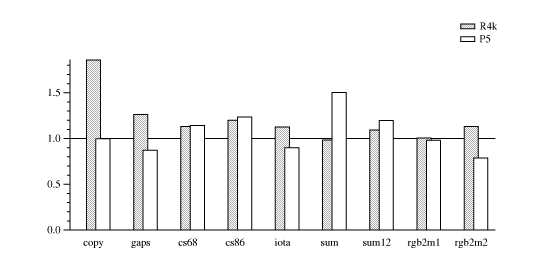
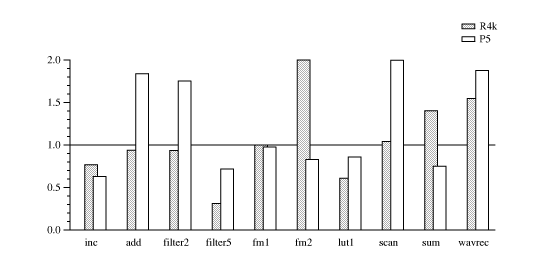
There are two groups of examples, the audio group (Figure simaud) and the video group (Figure simvid). The audio group uses 2000-byte buffers and 16-bit signals; the video group uses 4000-byte buffers and mostly 8-bit signals.
The graphs show the ratio of the execution time of the code generated by Simple to manually written C code. The data indicate that, with some exceptions, the runtimes are comparable. I suspect the exceptions result from aliasing preventing GCC's CSE.
In the audio group, this code was written using short* pointers
and processing one sample per iteration. In the video group, the code
was written using whole-word memory operations and immediate-mode
shifts/masks. Some of the code appears in Appendix manual.
Some of the static information used to create the specialized loops
appears in Appendix benche. These are generally arguments to
the interpreter copy, which is used for all the audio examples.
The video examples also use copy, except iota, sum, and sum12.
The audio examples operate on sequential aligned 16-bit data unless noted otherwise:
The video examples operate on sequential aligned 8-bit data unless noted otherwise:
 ps
ps
 ps
ps